| Version 3 (modified by , 8 years ago) ( diff ) |
|---|
Variance Reduction
General considerations
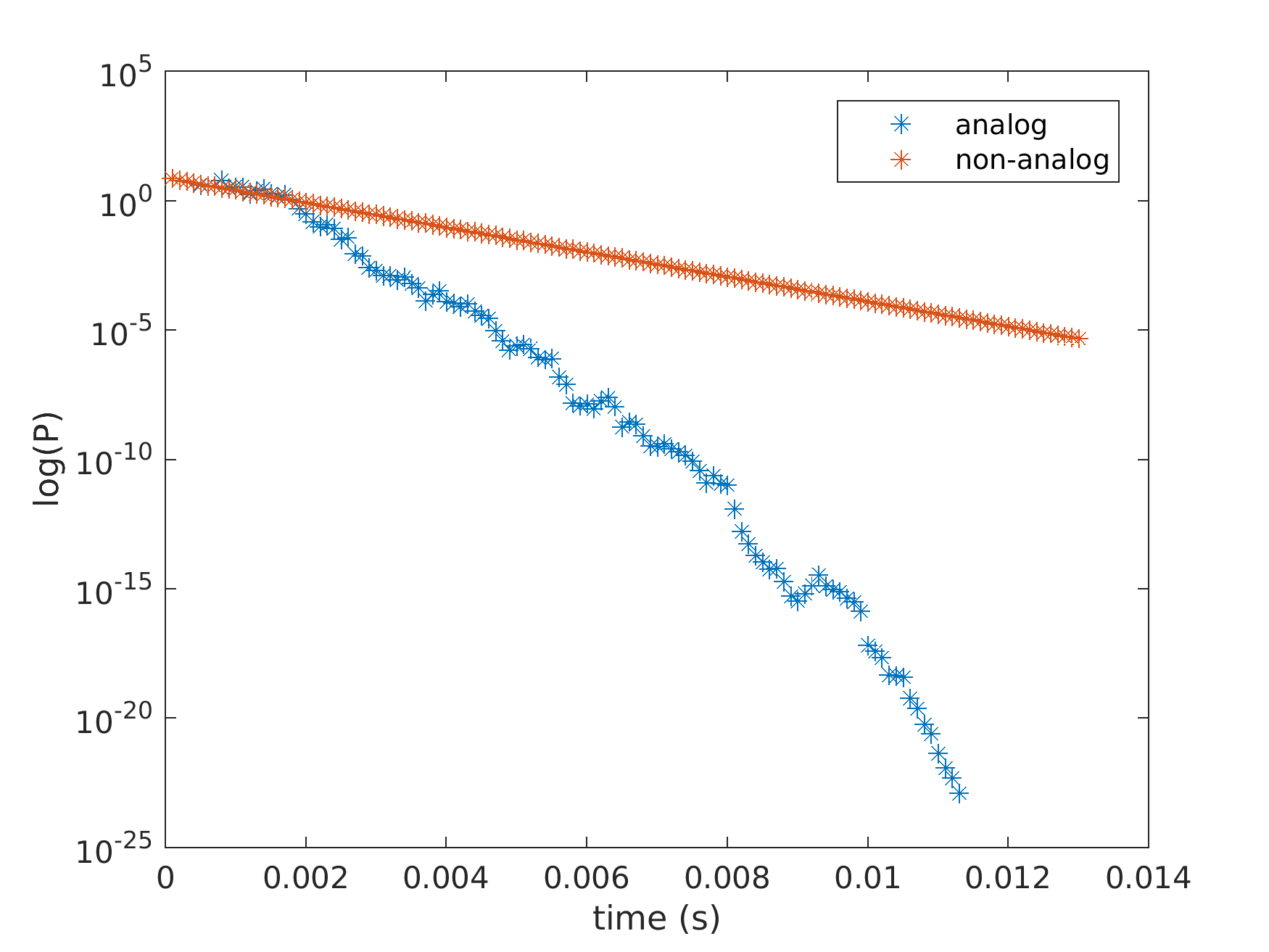
The time dependent tracking of the neutron population in a multiplying, near critical medium is very challenging in terms of Monte Carlo convergence. A naive analog game in most cases would statistically diverge, moreover it will give an underestimate of the power as the very low chance contributions of a high number of fission in certain chains see Fig. 1. Therefore the calculation is performed always keeping a single particle as a sample of the neutron population gaining or loosing weight at interactions. The neutron weight distribution must be kept around the mean for ensuring statistical convergence. The neutrons are followed from time interval to time interval and the population at the interval ends using splitting and Russian roulette while keeping the total population number constant. Having single, non-branching calculations also supports the architecture of the GPU where threads can be set to single neutron chains.

Figure 1.: Analog and non-analog simulation results for time dependent power evolution for a multiplying medium. Analog simulation produces an underestimate of the power
Biased sampling schemes are applied at fission yield, delayed neutron, interaction type sampling with ongoing development regarding path length sampling and angular biasing.
Optimization of the GPU workflow: history based vs. event based simulations
The key idea of GUARDYAN is a massively parallel execution structure making use of advanced programming possibilities available on CUDA enabled GPUs. In order to maximize performance however, the architecture calls for some major deviations from a traditional MC code.
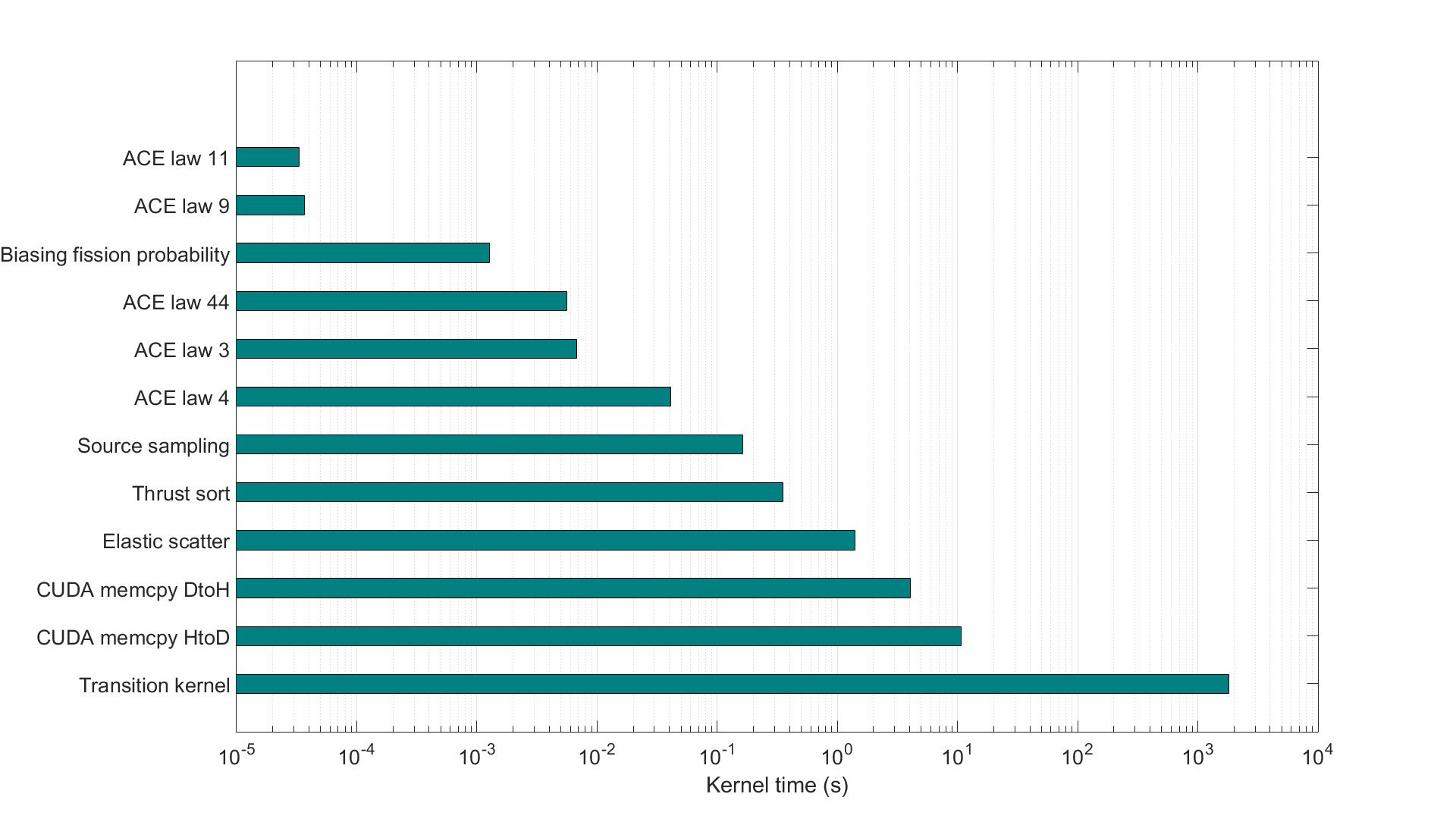
We have established two independent branches of the code, both designed to exploit the parallel capabilities of the GPU, although via quite different strategies. The first branch uses a very straightforward approach, that is the concurrent simulation of particle histories. One working unit is designated to simulate a particle history from birth to death, following the traditional history based structure. This idea exploits the inherent parallelism of MC tracking, i.e. particle histories are independent of each other. On the other branch the code is vectorized, meaning that simultaneously executed operations are expected to be identical. While vectorization of the code would not mean much difficulty in case of deterministic methods, MC simulations are ill-suited for this task by the random nature of the process. Preserving a history-based structure is in this case unfeasible, thus an event-based strategy was implemented. A parallel MC calculation is called event-based when only particles undergoing the same event are simulated concurrently. In this case, one working unit is assigned to calculate the outcome of one event in a particle history. The tracking routine first assigns events (e.g. free-flight, fission, elastic scatter) to particles, creating stacks of particles undergoing the same event, then these stacks are processed separately.
Parallel optimization structures
Currently GUARDYAN runs on a machine containing two Nvidia GeForce GTX 1080 cards, eachwith 8 GBytes of global memory and 5500 GFLOP/s single precision performance accordingto NBody GPU benchmark. The GTX 1080 cards are based on the Pascal architecture and have2560 scalar working units (CUDA cores). These cores can launch warps of 32 concurrent threads,resulting in a theoretical maximum of 81920 parallel working units. The optimal number of concurrentthreads may of course differ due to memory and arithmetic latency considerations. Threadmanagement is implemented by organizing a desired number of threads into blocks, which are requiredto execute independently. This also ensures automatic scalability of the program, as blocksof threads can be scheduled on any multiprocessors of the device, yielding faster execution timewhen more multiprocessors are available. Functions executed in parallel are called kernels in CUDAterminology. Kernels are launched by specifying the number of threads in a block, and the totalnumber of blocks. In general, to choose the number of threads in a block as a multiple of warp size(32) is a good idea, however, CUDA offers an opportunity to maximize kernel performance automatically: calling the cudaOccupancyMaxPotentialBlockSize function for every kernel ensuresoptimal occupancy in terms of arithmetic intensity and memory latency.
Memory Management
CUDA distinguishes six memory types: register, local, shared, texture, constant and global memory.Registers ensure the fastest memory access and are assigned to each thread. Global, constant and texture memory can be accessed by all threads, while the scope of shared memory is only ablock. In exchange, it is much faster. Texture memory is not truly a distinct memory type, it onlylabels a part of global memory that is bound to texture. Textures are implemented with hardwareinterpolation, thus they would be ideal for storing cross section data. But due to random memoryaccess patterns inherent in MC simulations, using cached memory is not advised in this case ,thus cross sections are stored in global memory. A severe limitation for MC applications is the sizeof global memory, e.g. in GUARDYAN, nuclear data for one temperature occupies about 6GB ona card with global capacity of 8GB. Memory transactions between GPU (device) and CPU (host) are carried outthrough reading and writing global memory. As the access of global memory is slow, these transactionscan also take a considerable time, and can have a significant impact on overall performance.Notice, that if the simulation structure is changed (e.g. a history-based algorithm is vectorized),register use, global memory reads and host-device communication will show different behavior,also influencing runtime. Thus the performance gain from vectorization will be obscured.

Attachments (7)
- NRDI.jpg (34.8 KB ) - added by 8 years ago.
- TDMCC_varP_analog_vs_nonanalog.png (61.8 KB ) - added by 8 years ago.
- event_vs_history_times_new.m.png (106.7 KB ) - added by 8 years ago.
- UOH2O_geometry.png (246.7 KB ) - added by 8 years ago.
- BME_OR_1e-6s_n2e26_neutrondensity_Guardyan_v3.jpg (528.0 KB ) - added by 8 years ago.
- BMEOR_v3.jpg (1.2 MB ) - added by 8 years ago.
- bmeor_profile.png (74.6 KB ) - added by 8 years ago.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}